

目录
快速导航-
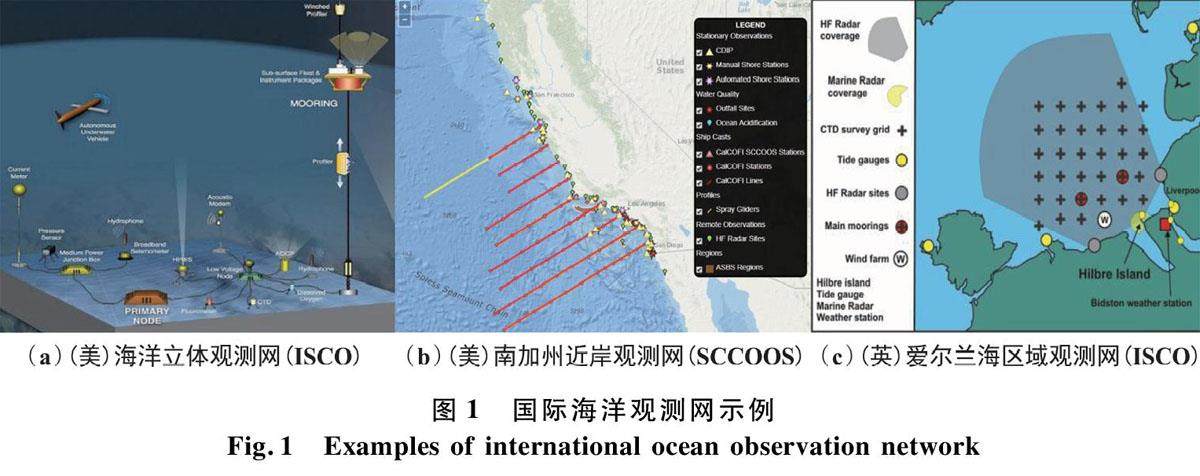
专家视点 | 海上跨平台无人系统机动组网与智能控制技术
专家视点 | 海上跨平台无人系统机动组网与智能控制技术
-
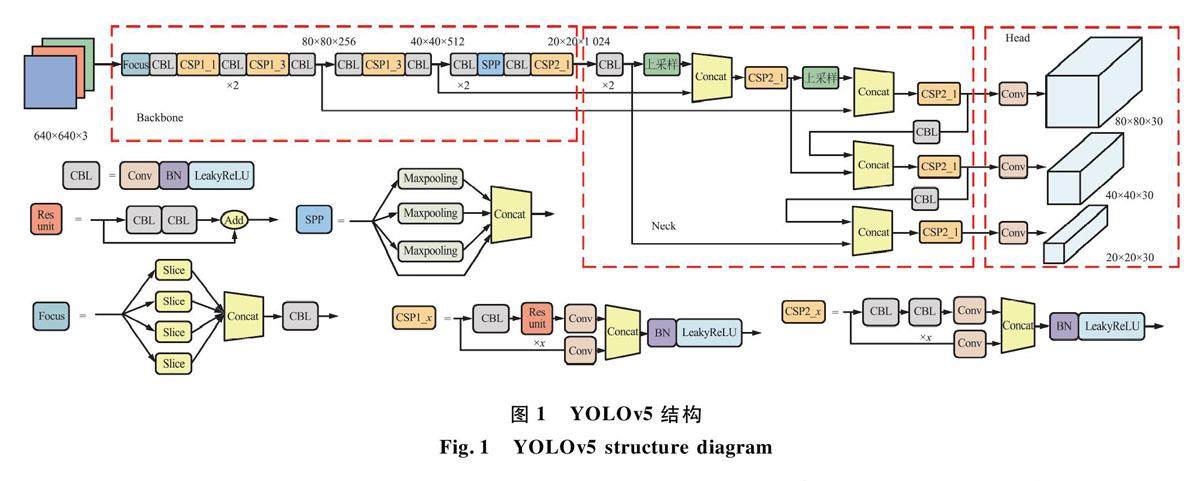
信号与信息处理 | 基于改进YOLO v5的雾霾天气下行人车辆检测算法
信号与信息处理 | 基于改进YOLO v5的雾霾天气下行人车辆检测算法
-

信号与信息处理 | 基于语义协同指导的小样本语义分割算法
信号与信息处理 | 基于语义协同指导的小样本语义分割算法
-

信号与信息处理 | 基于显著特征分类的立体图像重定向方法
信号与信息处理 | 基于显著特征分类的立体图像重定向方法
-
信号与信息处理 | 基于深度学习的PCB焊锡缺陷检测
信号与信息处理 | 基于深度学习的PCB焊锡缺陷检测
-

信号与信息处理 | 重参数化YOLO v5s的森林火灾检测算法
信号与信息处理 | 重参数化YOLO v5s的森林火灾检测算法
-
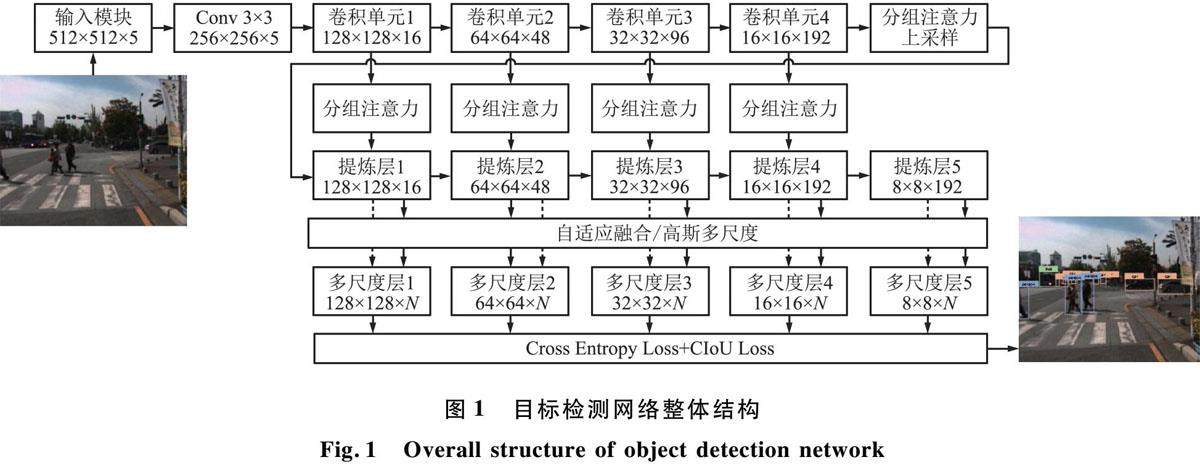
信号与信息处理 | 基于分组注意力和高斯多尺度的目标检测方法研究
信号与信息处理 | 基于分组注意力和高斯多尺度的目标检测方法研究
-

信号与信息处理 | 基于改进PSF估计的车载复杂图像复原
信号与信息处理 | 基于改进PSF估计的车载复杂图像复原
-

信号与信息处理 | 基于DeformebleDETR的自然场景任意形状文本检测
信号与信息处理 | 基于DeformebleDETR的自然场景任意形状文本检测
-
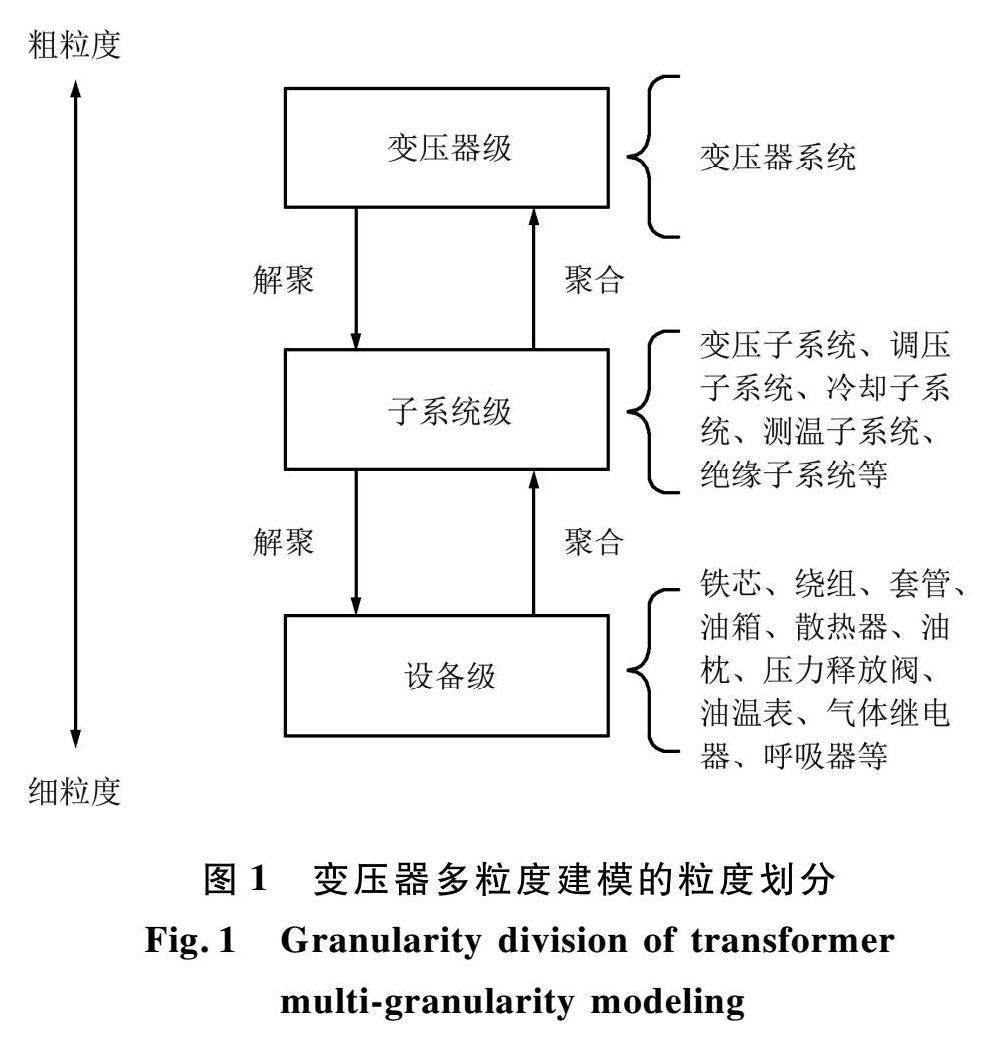
信号与信息处理 | 基于数字孪生的变压器多粒度建模与仿真分析
信号与信息处理 | 基于数字孪生的变压器多粒度建模与仿真分析
-

信号与信息处理 | 改进YOLO v7的晶圆字符检测算法
信号与信息处理 | 改进YOLO v7的晶圆字符检测算法
-

信号与信息处理 | 基于L型声阵列多重信号分类声源测向研究
信号与信息处理 | 基于L型声阵列多重信号分类声源测向研究
-
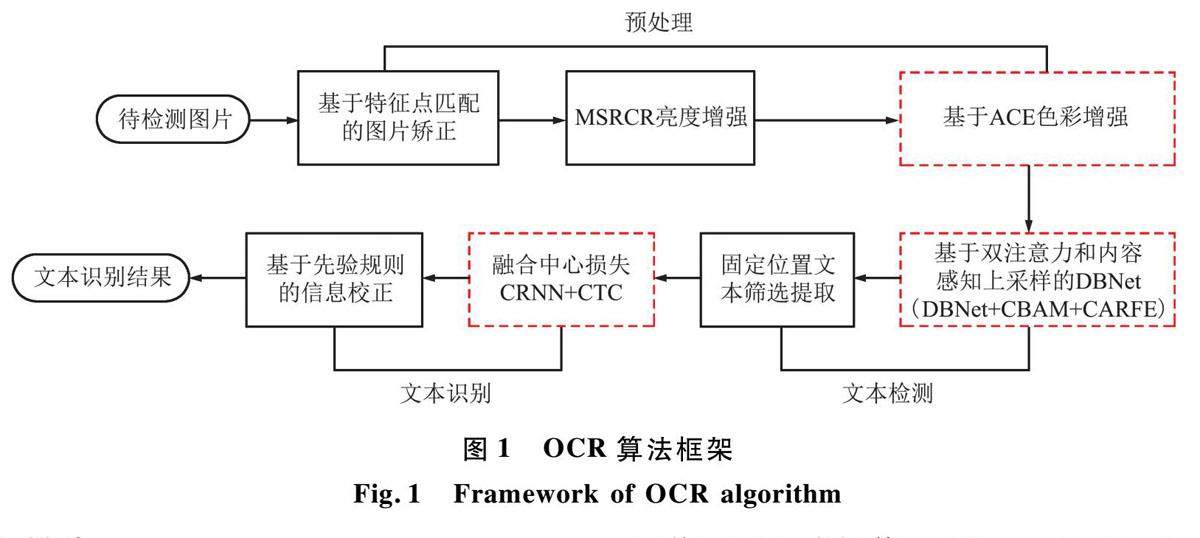
信号与信息处理 | 双注意力机制的复杂场景文字识别网络
信号与信息处理 | 双注意力机制的复杂场景文字识别网络
-
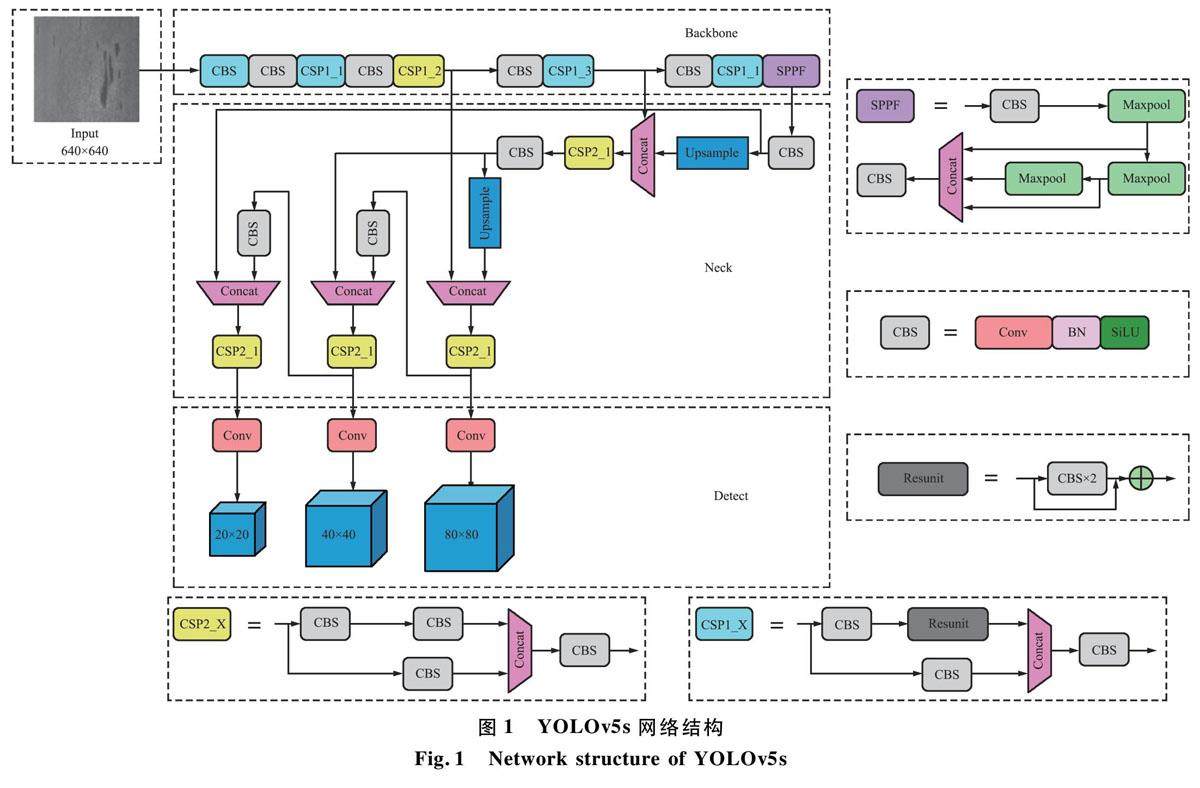
信号与信息处理 | 基于YOLO v5的钢材表面缺陷检测算法
信号与信息处理 | 基于YOLO v5的钢材表面缺陷检测算法
-

信号与信息处理 | 基于孪生网络的铁路复杂场景目标跟踪算法
信号与信息处理 | 基于孪生网络的铁路复杂场景目标跟踪算法
-
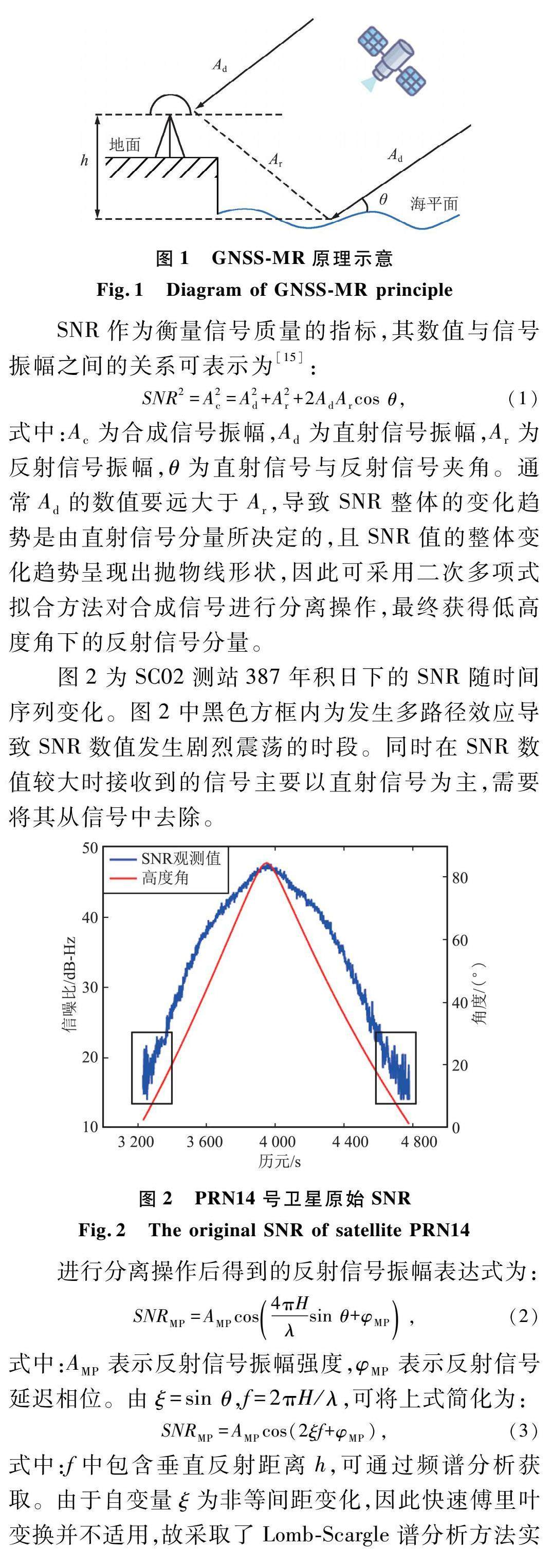
测控遥感与导航定位 | 一种GNSS MR海平面高度反演模型研究
测控遥感与导航定位 | 一种GNSS MR海平面高度反演模型研究
-
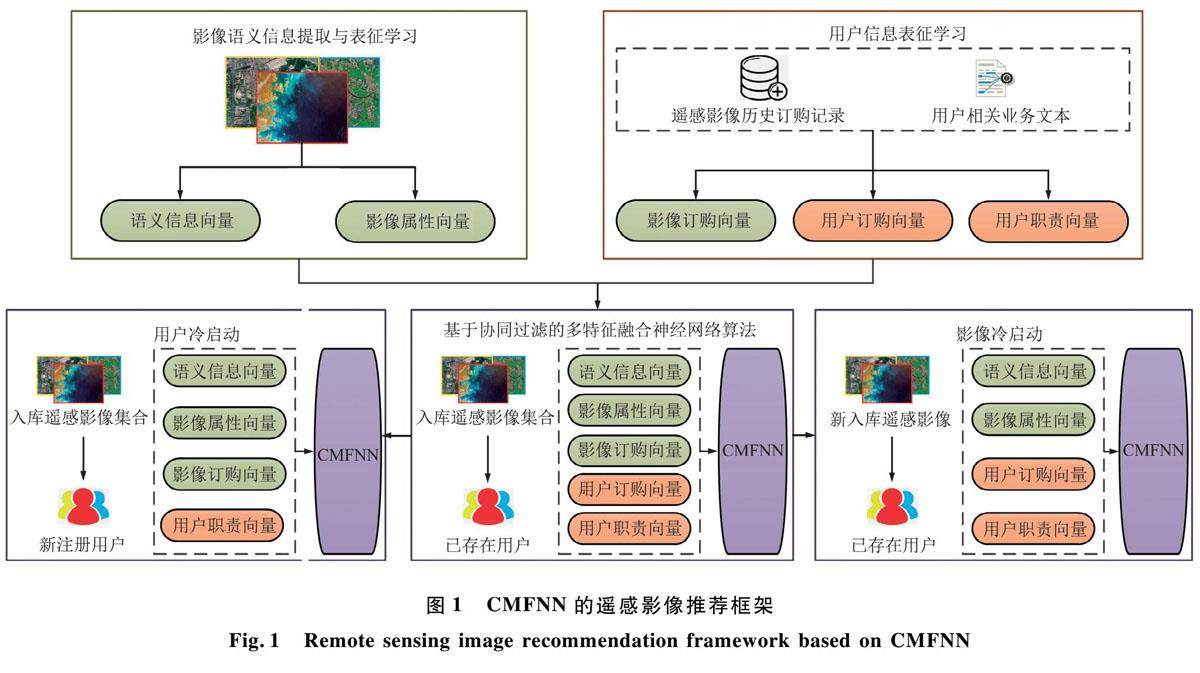
测控遥感与导航定位 | 基于多特征融合神经网络的遥感影像推荐方法
测控遥感与导航定位 | 基于多特征融合神经网络的遥感影像推荐方法
-
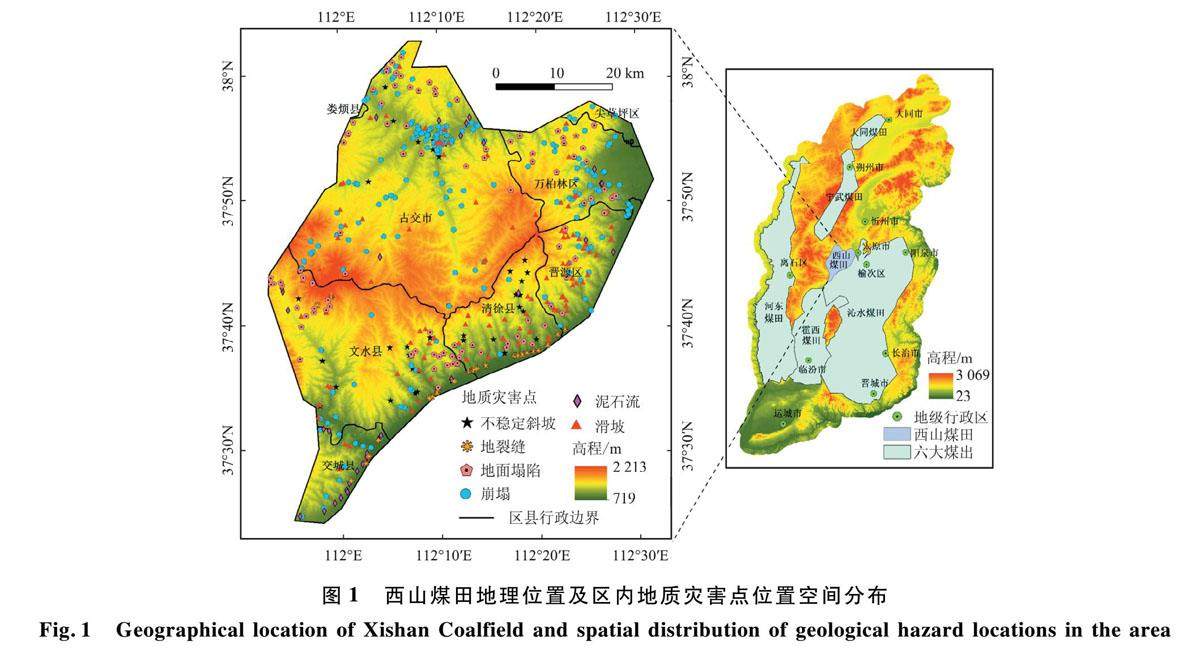
测控遥感与导航定位 | 信息量法耦合机器学习模型的西山煤田滑坡易发性评价
测控遥感与导航定位 | 信息量法耦合机器学习模型的西山煤田滑坡易发性评价
-
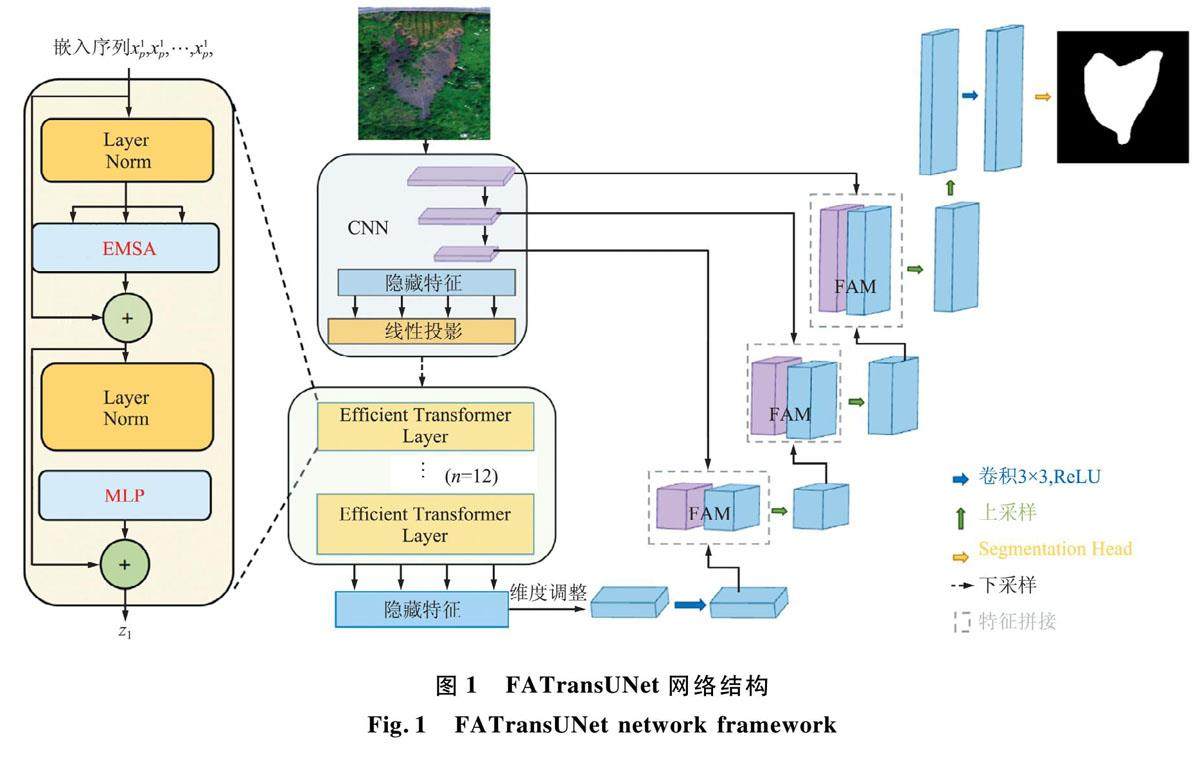
测控遥感与导航定位 | 一种改进Trans UNet的高分辨率遥感影像滑坡提取方法
测控遥感与导航定位 | 一种改进Trans UNet的高分辨率遥感影像滑坡提取方法
-
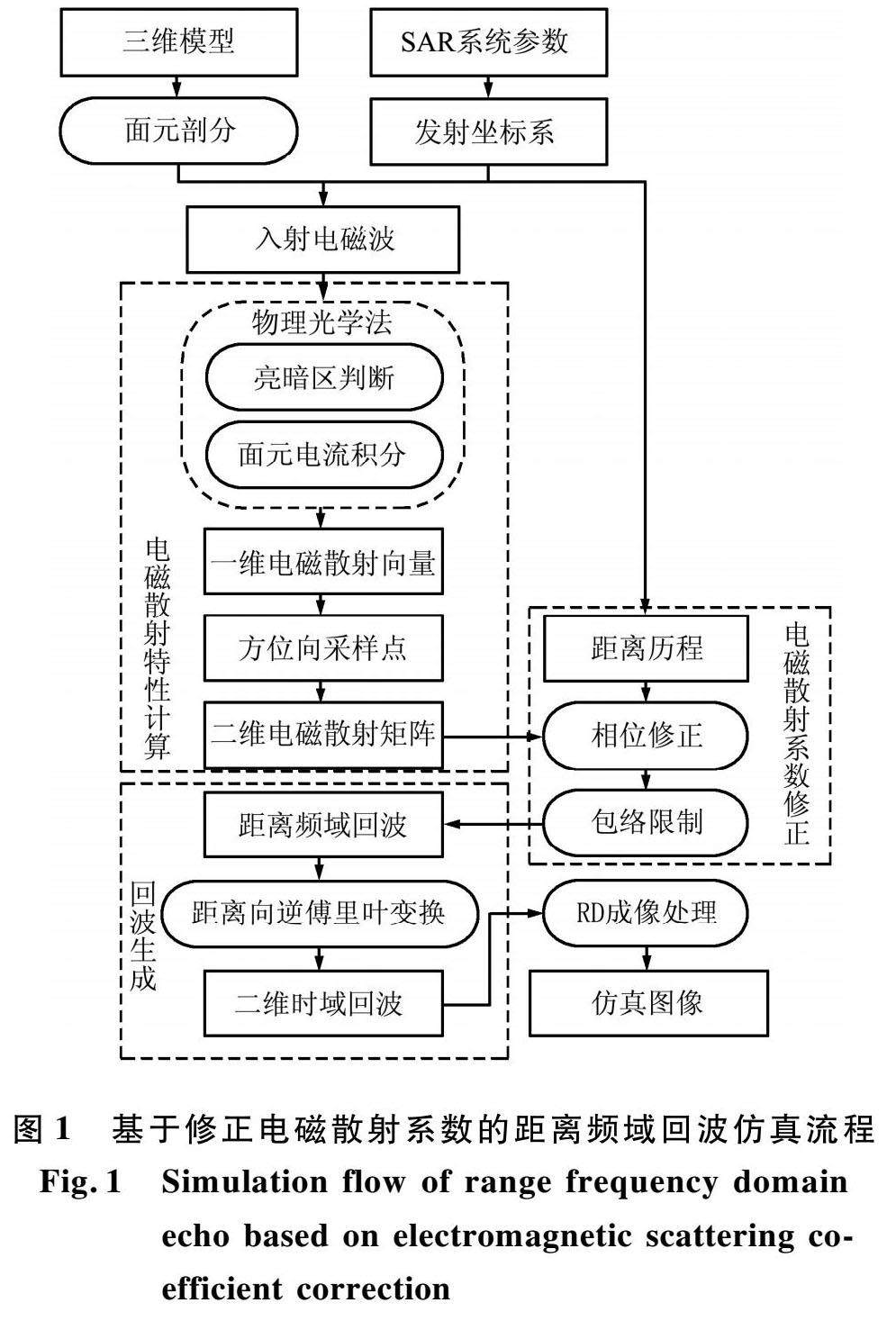
电磁场与微波 | 基于修正电磁散射系数的距离频域脉冲相干法SAR回波仿真
电磁场与微波 | 基于修正电磁散射系数的距离频域脉冲相干法SAR回波仿真
-

电磁场与微波 | 典型材料的高空核电磁脉冲屏蔽效能评估
电磁场与微波 | 典型材料的高空核电磁脉冲屏蔽效能评估
-

电磁场与微波 | 河北区域电离层精细建模及磁暴响应特征研究
电磁场与微波 | 河北区域电离层精细建模及磁暴响应特征研究
-
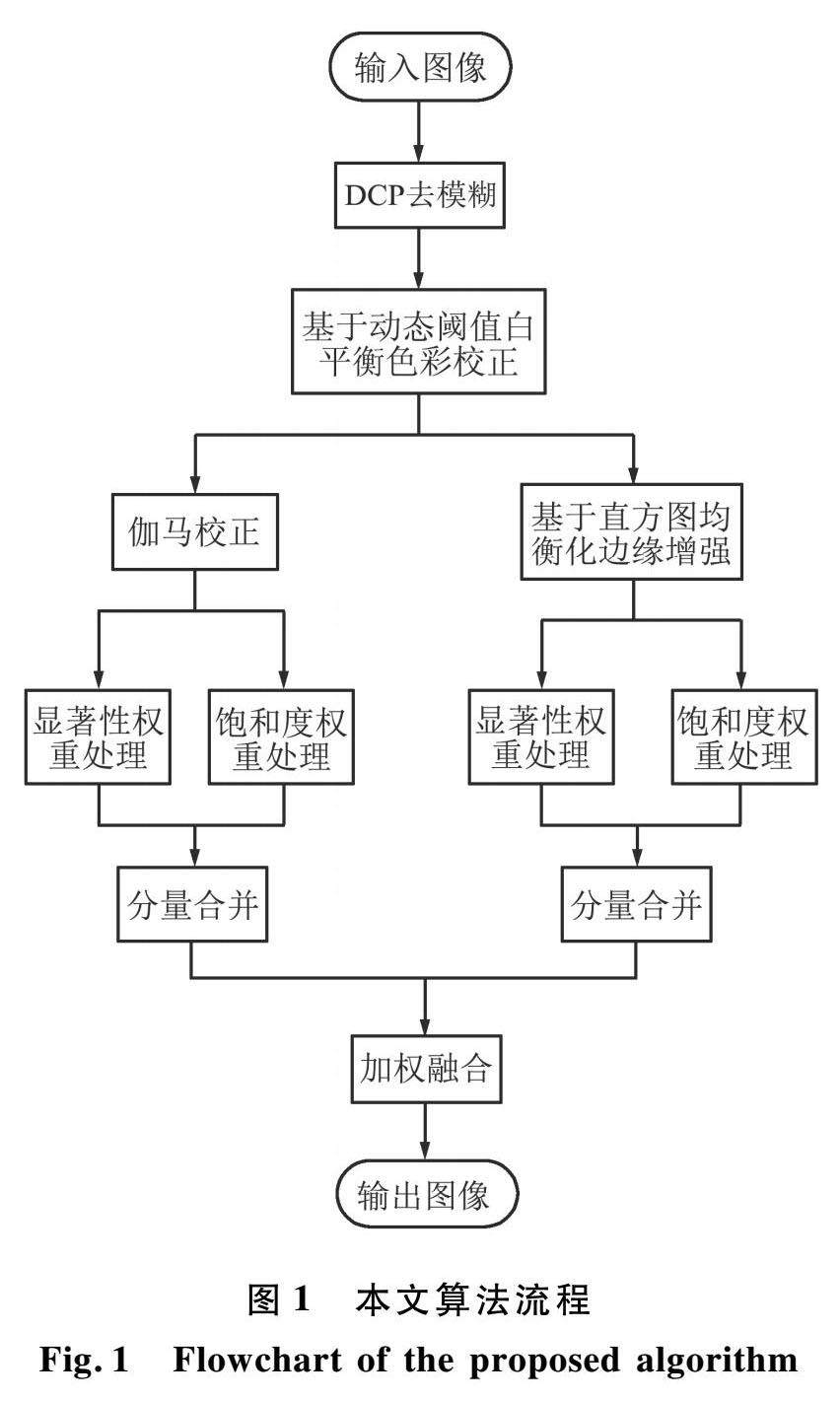
工程与应用 | 基于色彩均衡和多权重融合的水下图像增强算法
工程与应用 | 基于色彩均衡和多权重融合的水下图像增强算法
-

工程与应用 | 倾斜地面3D点云快速分割算法
工程与应用 | 倾斜地面3D点云快速分割算法
-

工程与应用 | 基于CEVA XC4500DSO平台5G LDPC码编码实现
工程与应用 | 基于CEVA XC4500DSO平台5G LDPC码编码实现
-

工程与应用 | 基于分级思想的多级蚁态蚁群改进算法
工程与应用 | 基于分级思想的多级蚁态蚁群改进算法
-
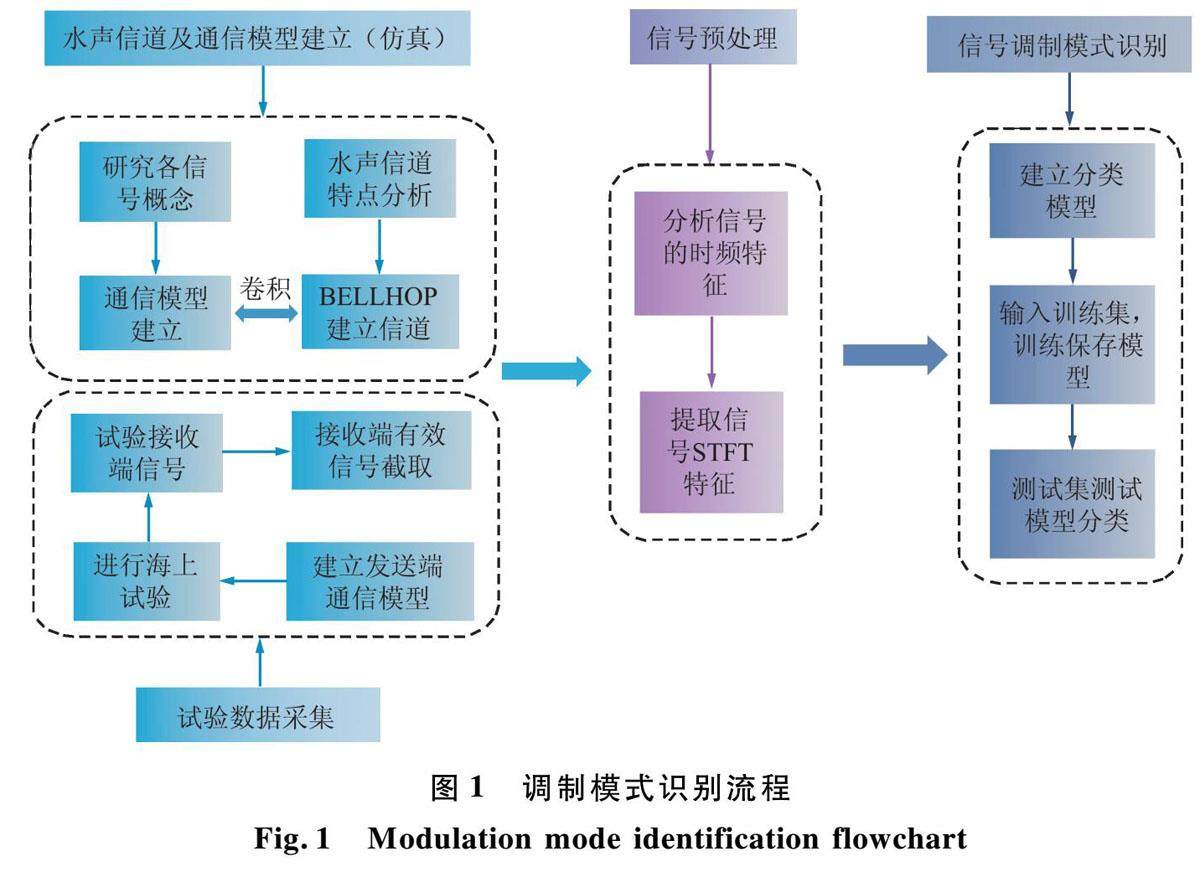
工程与应用 | 基于残差时序卷积网络的水声通信信号模式识别
工程与应用 | 基于残差时序卷积网络的水声通信信号模式识别
-
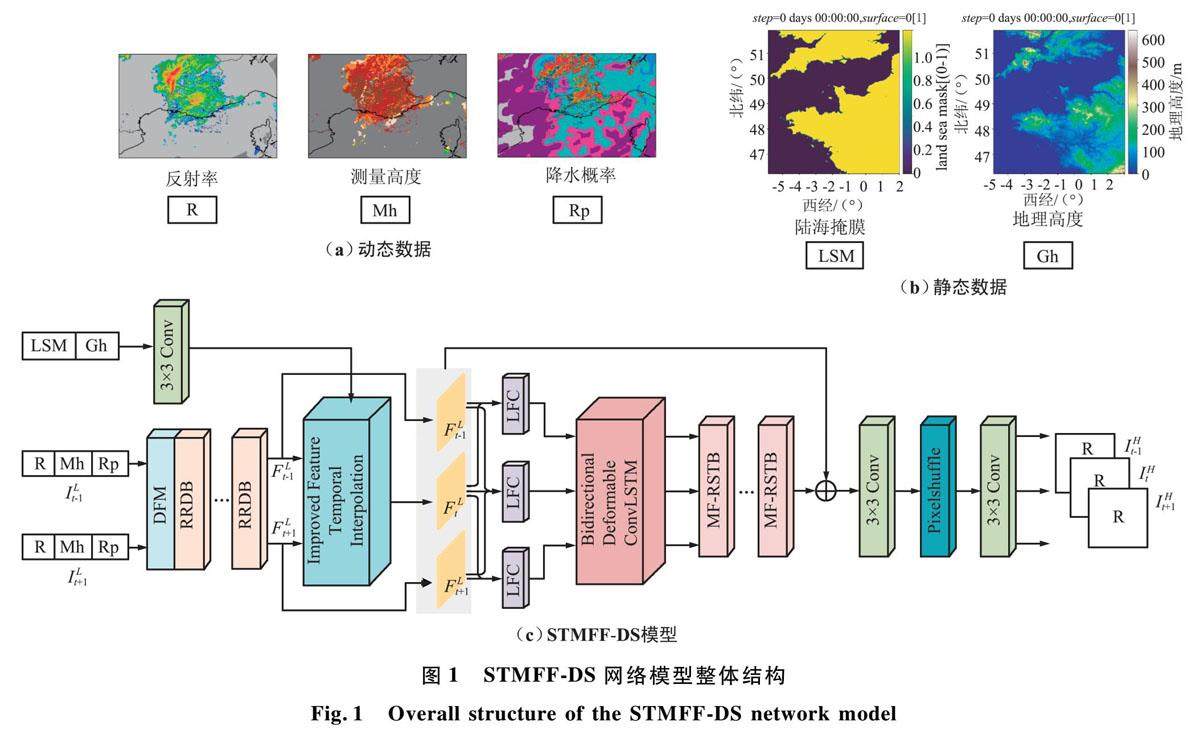
工程与应用 | 一种多气象特征融合的时空降尺度模型
工程与应用 | 一种多气象特征融合的时空降尺度模型
-

工程与应用 | 基于多重高阶同步压缩的高动态信号捕获技术
工程与应用 | 基于多重高阶同步压缩的高动态信号捕获技术
-

工程与应用 | 基于改进Centerfusion的自动驾驶3D目标检测模型
工程与应用 | 基于改进Centerfusion的自动驾驶3D目标检测模型





















 登录
登录